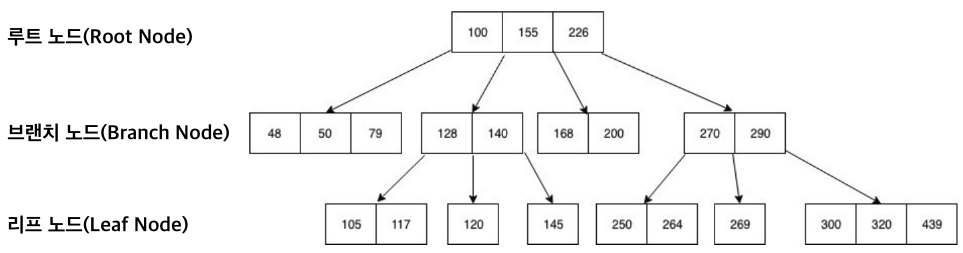
B Tree 구조
- 자식 2개만을 갖는 이진 트리(Binary Tree)를 확장하여 N개의 자식을 가질 수 있음
- 좌우 자식 간의 균형이 맞지 않을 경우 비효율적이라 항상 균형을 맞춘다는 의미로 균형 트리라고도 부름
페이지
디스크와 메모리(버퍼풀)에 데이터를 읽고 쓰는 최소 작업 단위
일반적인 인덱스를 포함해 PK(클러스터 인덱스)와 테이블 등은 모두 페이지 단위로 관리된다.
ex. 쿼리를 통해 1개의 레코드를 읽는다 -> 하나의 블록을 읽어야함.
페이지에 저장되는 개별 데이터의 크기를 최대한 작게하여,
1개의 페이지에 많은 데이터를 저장할 수 있도록 하는 것이 중요
B-Tree 인덱스의 구조
테이블
CREATE TABLE employee (
emp_no INT NOT NULL AUTO_INCREMENT,
name VARCHAR(64),
PRIMARY KEY(emp_no),
INDEX idx_name (name)
) ENGINE=InnoDB;
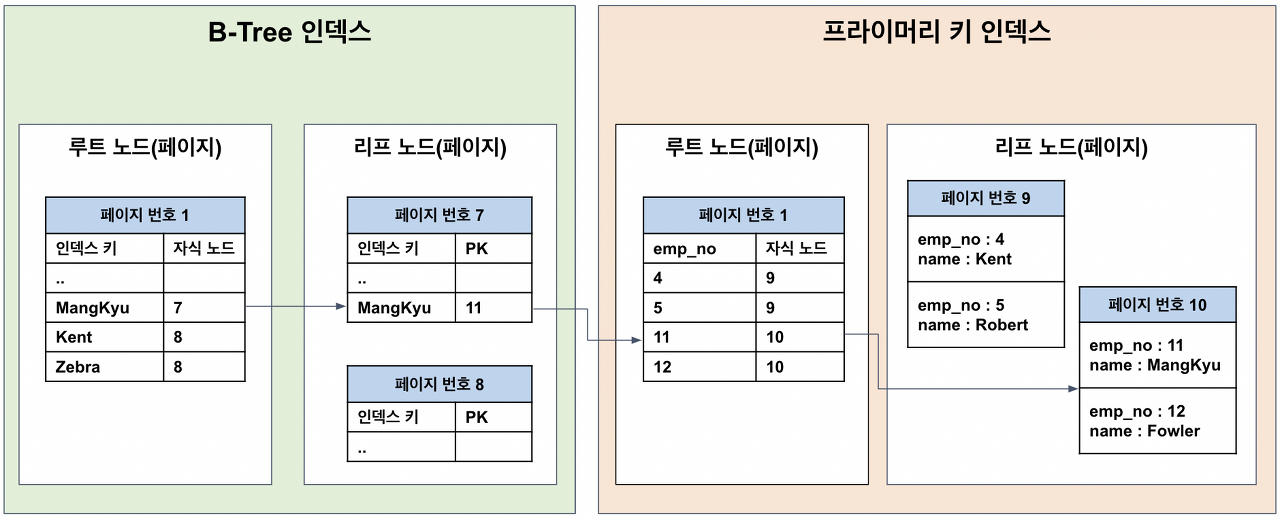
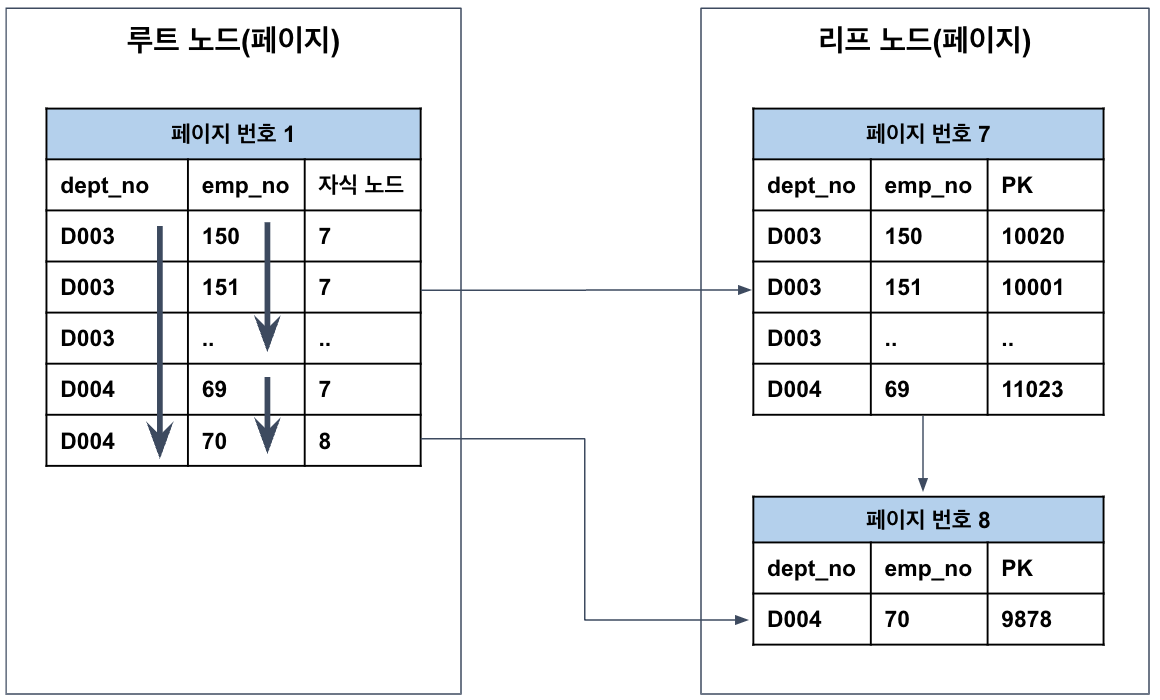
모든 페이지는 키 값을 기준으로 정렬되어 있으며 idx_name 인덱스의 경우, name을 기준으로 정렬되어 있고, 데이터를 따라 리프노드에 도달하면 인덱스 키에 해당하는 레코드의 PK 값이 저장되어 있다.
인덱스는 테이블과 독립적인 저장 공간이므로 인덱스를 통해 데이터를 조회하려면 먼저 PK를 찾아야 한다. PK로 레코드를 조회할 때는 (인덱스 영역에서 테이블 영역으로 넘어가는 경우) PK가 어느 페이지에 저장되어 있는지 알 수 없으므로 랜덤 I/O가 발생하게 된다. 이후에는 PK를 따라 리프노드에서 실제 레코드를 읽어온다. 참고로 연속된 데이터를 조회하는 경우에는 순차 I/O가 발생하는데, 랜덤 I/O는 임의의 장소에서 데이터를 가져오지만 순차 I/O는 다음 장소에서 데이터를 가져오므로 훨씬 빠르다.
인덱스가 필요한 이유
인덱스를 통해 조회하는 것은 아래 2개의 작업이 수행된다.
- 인덱스를 통해 PK를 찾는다.
- PK를 통해 레코드를 찾는다.
옵티마이저는 인덱스를 통해 레코드 한 건을 읽는 것이 테이블을 통해 직접 읽는 것 보다 4~5배 정도 비용이 더 많이 들 것으로 예측한다.
따라서, 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 사용하지 않는 것이 효율적이다. (옵티마이저의 역할)
인덱스 사용에 영향을 주는 요소
PK의 크기
PK가 레코드의 물리적인 저장 위치를 결정하기 때문에, 인덱스는 PK에 의존한다.
그래야 인덱스를 타고 들어와서 PK를 통해 레코드의 값을 읽어올 수 있기 때문이다.
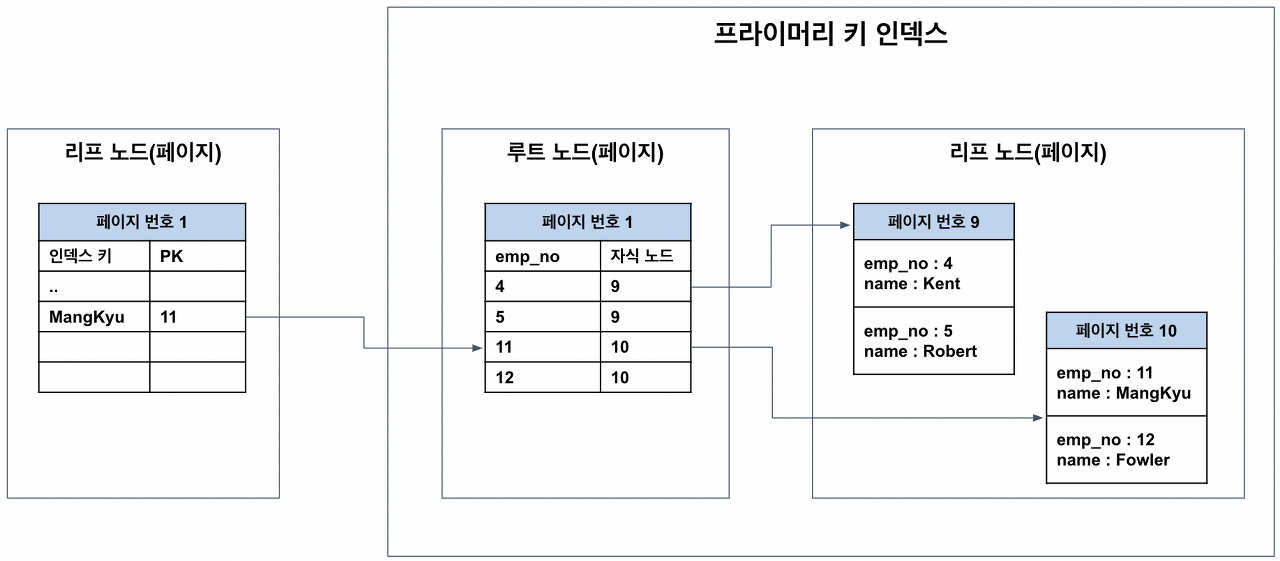
인덱스가 PK가 아닌 실제 레코드의 주소를 갖게 할 수도 있지만, 그러면 PK가 변경될 때 레코드의 주소가 변경되고 모든 인덱스에 저장된 레코드 주소를 변경해야 한다. 이러한 오버헤드를 피하기 위해 인덱스는 레코드의 주소가 아닌 PK를 저장하고 있다.
따라서 PK값이 클수록 인덱스에 좋지 않다.
PK가 클수록 한 페이지에 담을 수 있는 인덱스 정보도 줄어들고, 메모리도 비효율적으로 사용되기 때문이다.
또한 트리의 깊이도 지나치게 깊어지면 읽어야 하는 페이지가 많아져 성능에 좋지않다.
인덱스의 컬럼 순서
(PK를 포함하여) 인덱스는 여러 개의 컬럼으로 구성될 수 있는데, 이를 다중 컬럼 인덱스라고 부른다.
ex.
CREATE TABLE `dept_emp` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_no` varchar(100) NOT NULL,
`emp_no` varchar(100) NOT NULL,
INDEX idx_dept_emp (`dept_no`, `emp_no`),
PRIMARY KEY (`id`)
);
두 번째 컬럼은 첫 번째 컬럼에 의존하여 정렬된다.
두 번째 컬럼만으로 질의를 할 경우 인덱스를 타지 못한다.
즉, 두 번째 컬럼의 정렬은 첫 번째 컬럼이 동일한 레코드에서만 의미가 있다. -> 컬럼 순서 중요 !!
카디날리티
카디날리티란 특정 컬럼에 존재하는 데이터의 고유성을 말한다.
카디날리티가 높을수록 중복도가 낮아지며 유니크한 값이 많아진다는 것이다.
ex.
CREATE TABLE `dept_emp` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`dept_no` varchar(100) NOT NULL,
`emp_no` varchar(100) NOT NULL,
INDEX idx_dept (`dept_no`),
PRIMARY KEY (`id`)
);
위 테이블에 레코드가 10000건이 있으며, 2가지 케이스가 있다.
- 케이스 A
- dept_no 컬럼의 유니크한 값이 10개
- 1개의 dept_no에 평균 1000개(10000/10)의 emp_no가 저장됨
- 케이스 B
- dept_no 컬럼의 유니크한 값이 1000개
- 1개의 dept_no에 평균 10개(10000/1000)의 emp_no가 저장됨
SELECT * FROM dept_emp WHERE dept_no = 'D003' AND emp_no = '150';
위 쿼리를 실행 결과
- 케이스 A : 1000개의 결과, 999개가 추가로 읽혀짐
- 케이스 B : 10개의 결과, 9개가 추가로 읽혀짐
이러한 이유로 일반적인 인덱스는 유니크할수록 효율적이다. 하지만 카디날리티가 낮더라도 정렬 또는 그루핑 등에 효율적으로 사용될 수 있으므로, 용도에 맞게 적절히 설계하여야 한다.
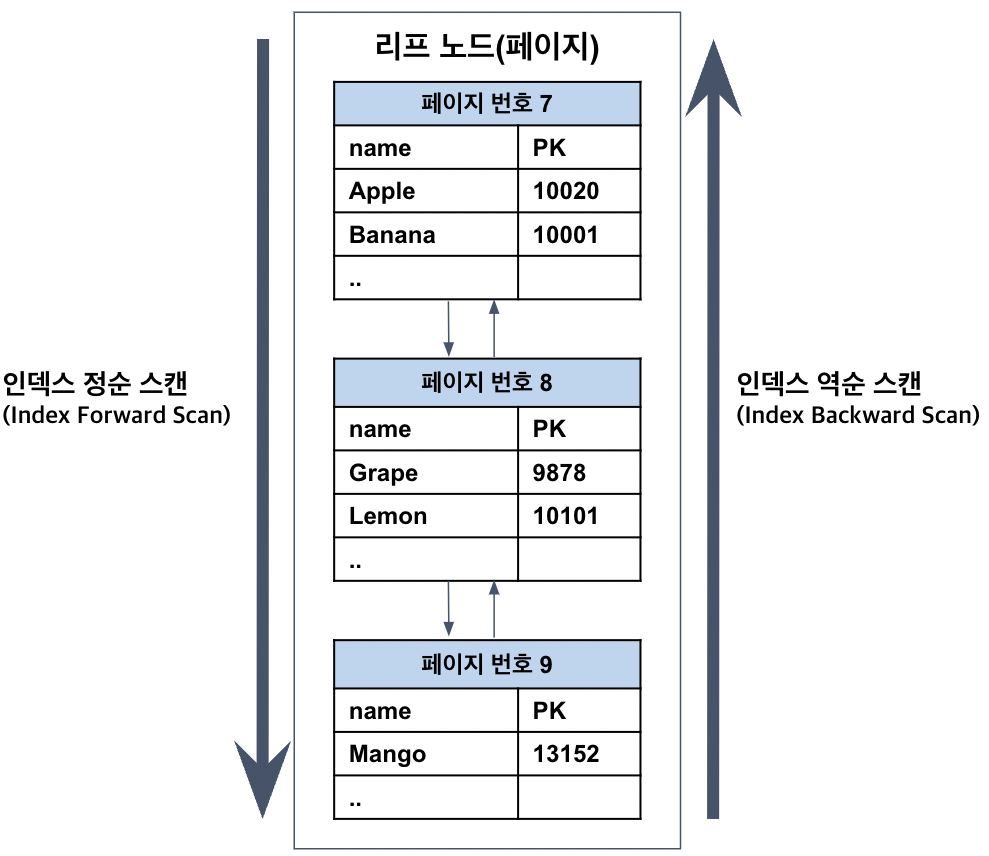
인덱스의 정렬 및 스캔 방향
인덱스는 설정된 정렬 규칙에 따라 정렬되어 저장된다.
ex.
CREATE INDEX idx_dept_emp (`dept_no`, `emp_no`) ON employees (dept_no ASC, emp_no DESC);
인덱스를 정렬 순서대로만 읽을 수 있는 것은 아니다. 인덱스가 오름차순으로 생성되어도 내림차순으로 읽을 수 있다. 인덱스를 읽는 방향은 옵티마이저가 실시간으로 만들어내는 실행 계획에 따라 결정된다.
- 인덱스 정순 스캔 : 인덱스 순서대로 읽는다.
- 인덱스 역순 스캔 : 인덱스 반대 방향으로 읽는다.